Пользовательское поведение меняется быстрее, чем поисковые стратегии брендов. Все больше людей ищут информацию напрямую в ChatGPT, Perplexity, «Алисе» и других ассистентах — минуя классический поиск. В ответ они получают не набор ссылок, а готовые рекомендации: какой продукт выбрать, какой сервис использовать, какой компании можно доверять.

В этой логике нейросети начинают играть роль фильтра доверия. Они не просто пересказывают информацию из интернета, а отбирают источники, которые считают надежными, и могут упоминать бренд в ответе — как пример, рекомендацию или точку отсчета. Для компаний это означает новый уровень конкуренции: бороться нужно не за позицию в выдаче, а за место в ответе.
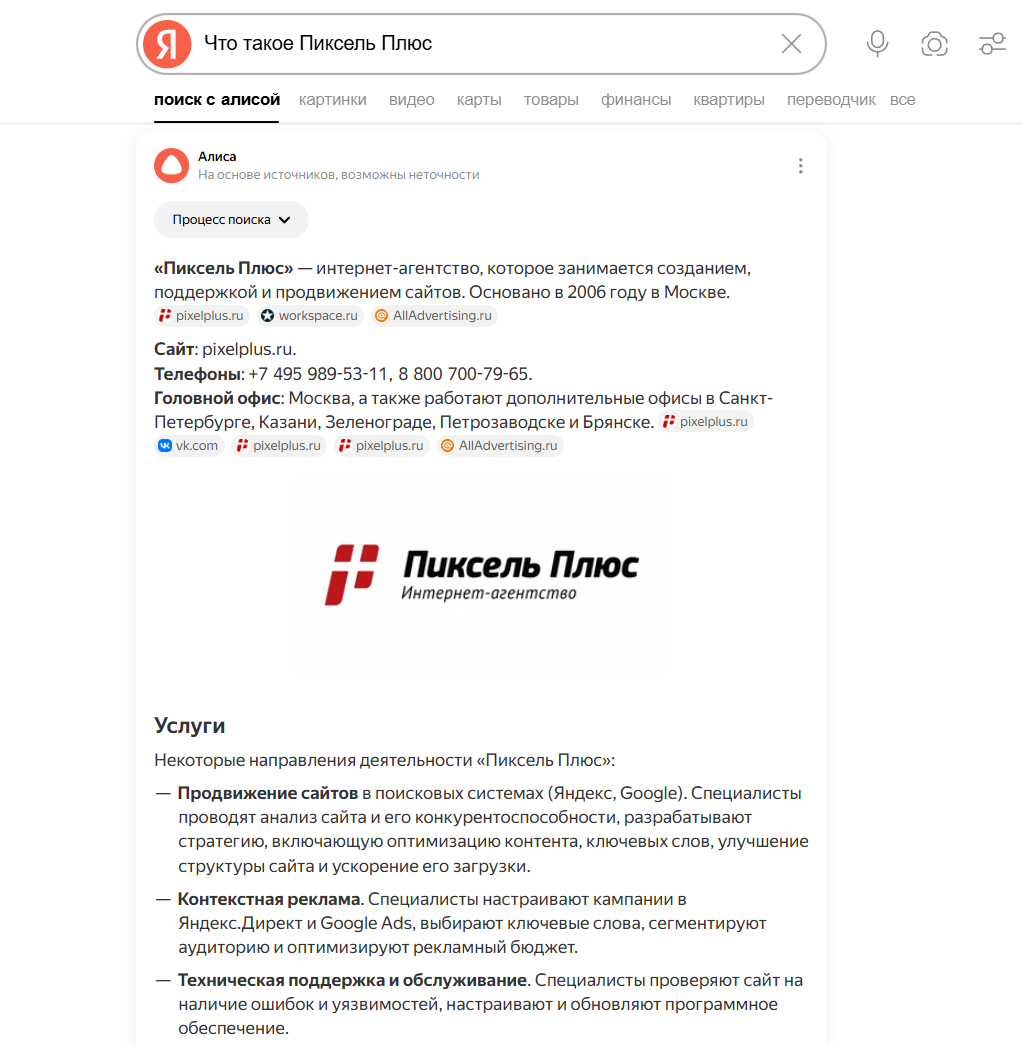
И здесь возникает парадокс. У компании может быть сильный, экспертный, качественный контент — статьи, исследования, кейсы, полезные материалы — но при этом он все равно не попадает в ответы нейросетей. Причина чаще всего не в слабом контенте, а в типичных ошибках, из-за которых нейросетевые алгоритмы просто не видят бренд как источник. Именно эти недочеты мешают даже сильным проектам становиться частью нейроответов.
Что это значит для бизнеса?
Появляется новая точка входа. Пользователь может перейти на сайт бренда, даже не сталкиваясь с ним в классической поисковой выдаче. Без рекламы, без UTM-меток, без прямого клика по объявлению — просто потому, что нейросеть нашла контент и сочла его подходящим для ответа.
Фактически нейросети начинают выполнять функцию рекомендательного слоя между пользователем и брендами. Они отбирают источники, на которые можно опереться, и все чаще упоминают конкретные компании как примеры или ориентиры. Для бизнеса это означает, что видимость формируется не только через SEO и рекламу, но и через то, как контент интерпретируется ИИ.
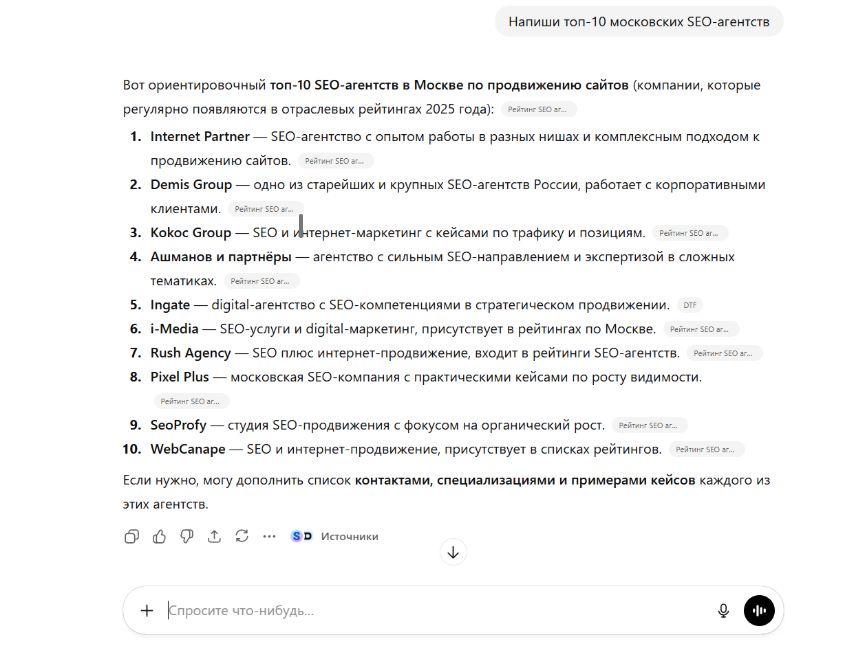
Расскажем о десяти самых распространенных ошибках, которые мешают брендам появляться в ответах нейросетей даже при мощном контенте. И заодно покажем, как с помощью инструмента Модуль анализа видимости в Пиксель Тулс проверить, видят ли популярные нейросети ваш бренд как источник, в каких сценариях он появляется и где именно теряется на уровне формулировок и структуры.
Ошибка №1. Контент создан с помощью нейросетей, но не адаптирован для нейроответов
Многие компании пользуются нейросетями для подготовки текстов для сайтов, блогов и других площадок. Это действительно ускоряет работу и помогает масштабировать контентную составляющую сайта. При этом проблема обычно не в самом факте использования ИИ, а в том, что получившийся материал воспринимается как «готовый».
Даже если контент по сути экспертный и достоверный, нейросети редко воспринимают такие тексты как надежный источник без дополнительной доработки. Сгенерированные материалы часто выглядят ровно и логично, но остаются слишком обобщенными. Им не хватает конкретики, примеров из практики, точных формулировок и контекста, который отличает реальный опыт компании от пересказа открытых источников.
Отдельный вопрос — структура. И люди, и нейросети лучше работают с материалами, где есть четкие смысловые блоки: подзаголовки, списки, короткие абзацы. Сплошной текст без визуальных и логических якорей превращается в шум, из которого сложно извлечь отдельные фрагменты для ответа.
Это особенно заметно при мультимодальных запросах. Если пользователь загружает документ или изображение, для нейросетей критично наличие читаемого текстового слоя, корректных названий файлов и alt-текстов. Без этого часть контента становится невидимой для ИИ.
Что надо учитывать:
- проверять факты и дополнять текст конкретными примерами и источниками;
- разбивать материал на логические блоки с подзаголовками;
- использовать списки и короткие абзацы, которые легко извлекаются из текста;
- адаптировать документы и изображения: текстовый слой вместо сканов, понятные названия файлов, подписи и alt-тексты.
Ошибка №2. Переоптимизация: текст формально «правильный», но неестественный для AI
ИИ-ассистенты и нейросети отдают предпочтение текстам, которые звучат естественно и передают смысл напрямую. Переоптимизированные текстовые портянки с перегруженными ключами и искусственными конструкциями сложнее интерпретировать: ИИ хуже понимает, о чем идет речь и какой фрагмент стоит использовать в ответе.
Особенно заметно это в голосовом поиске — например, в «Алисе». Если ключевая мысль спрятана в середине абзаца или выражена через сложные обороты, ассистент может обрезать ответ или не воспроизвести его вовсе. В результате даже полезный и корректный контент не попадает в нейроответ.
Что помогает снизить риск:
- формулировать мысли понятным языком;
- выносить ключевую идею в начало абзаца или смыслового блока;
- избегать метафор и образных выражений, которые нейросети могут интерпретировать буквально;
- не перегружать текст ключевыми словами — нейросети ориентируются на смысл, а не на плотность.
Сегодня выигрывает контент, который сочетает понятную структуру и живой язык. Это не отказ от оптимизации, а ее адаптация под логику AI — и один из базовых факторов, влияющих на попадание в нейроответы.
Ошибка №3. Один и тот же контент без адаптации размещается на всех площадках
Многие компании используют один и тот же материал сразу на нескольких площадках: публикуют статью на сайте, затем копируют ее в блог, на VC.ru, в Дзен и корпоративные соцсети. С точки зрения скорости вполне удобно, но для нейросетей это создает проблему.
Когда контент не адаптирован под конкретную площадку, он воспринимается как дубликат. Алгоритмы нейросетевого поиска в большинстве случаев выбирают только один источник для ответа. Остальные версии материала просто игнорируются — даже если по сути там все сильно и полезно. Бренд теряет видимость и реже появляется в рекомендациях.
Похожая ситуация возникает и внутри сайта, если публикуются близкие по смыслу или частично дублирующиеся материалы. Нейросети и поисковые алгоритмы не всегда понимают, какой из них основной, и в итоге могут не использовать ни один. В эпоху ИИ это одна из самых распространенных ошибок, которая снижает шансы попасть в нейроответы.
Дополнительный фактор — различия между площадками. У каждой из них свои алгоритмы, формат потребления контента и ожидания аудитории. Текст, который хорошо работает на сайте компании, может быть менее понятным или менее релевантным для нейросетей в контексте других платформ.
Что стоит учитывать:
- адаптировать структуру и подачу материала под конкретную площадку и ее аудиторию;
- варьировать заголовки, формулировки и смысловые акценты;
- избегать дословного копирования, чтобы не терять видимость и приоритет источника.
Ошибка №4. Контент не адаптирован под региональный контекст нейросетей
Нейросети, как и поисковые системы, учитывают географию пользователя. Это особенно заметно в экосистеме Яндекса — в «Алисе» и нейроответах, где рекомендации все чаще формируются с учетом региона. Даже качественный и релевантный контент может не попасть в ответ, если ИИ не понимает, для какой географии он применим.
Проблема здесь не в отсутствии локального бизнеса. Региональный контекст важен и для федеральных компаний: нейросети стараются соотносить информацию с условиями, рынком и инфраструктурой конкретной территории. Если в тексте нет региональных сигналов, модель не может корректно сопоставить его с запросом пользователя.
Контент остается обезличенным: он выглядит полезным в целом, но не привязывается к конкретной ситуации. Для ИИ это снижает приоритет источника, особенно в запросах, где география влияет на выбор услуг, подрядчиков или продуктов.
Что стоит проверить:
- указаны ли в контенте город или регион, если это влияет на предложение;
- есть ли на сайте раздел с контактной информацией и корректной микроразметкой;
- используются ли локальные формулировки там, где они действительно уместны, а не формально.
Региональная адаптация — сигнал для нейросетей о применимости контента. Без него даже сильные материалы могут не попадать в нейросетевую выдачу.
Ошибка №5. Устаревшие материалы формируют искаженную картину бренда для нейросетей
Нейросети работают не только с актуальными страницами сайта. Они опираются на весь массив информации о бренде, который доступен в открытых источниках: старые статьи, кейсы, публикации в СМИ, партнерские материалы, архивные версии страниц. Для ИИ-моделей вроде ChatGPT это особенно критично, поскольку представление о компании формируется на основе накопленных данных.
Если в сети остаются устаревшие материалы — с неактуальными услугами, условиями, географией или позиционированием, — именно они могут быть использованы в ответе нейросети. В результате пользователь получает информацию, которая не соответствует текущему состоянию бренда, и делает выводы на основе устаревших данных.
Проблема усугубляется тем, что нейросети не всегда различают «архив» и «актуальную версию». Для них важнее сам факт наличия информации и ее согласованность с другими источниками. Несоответствия и противоречия снижают доверие к бренду как к источнику и уменьшают вероятность его упоминания в рекомендациях.
Что помогает снизить риск:
- регулярно обновлять ключевые страницы и материалы, которые продолжают индексироваться;
- закрывать от поиска или архивировать неактуальные публикации;
- формировать новые упоминания на авторитетных площадках, включая СМИ и отраслевые ресурсы;
- отслеживать, какие формулировки и сведения о бренде используются в ответах нейросетей.
В контексте нейросетевой выдачи управление архивом контента становится частью работы с репутацией: устаревшая информация может влиять на образ бренда не меньше, чем новые публикации.
Ошибка №6. Технические и интерфейсные проблемы снижают приоритет страницы для нейросетей
Качество контента не гарантирует попадание в нейроответы. Нейросети оценивают страницу целиком — не только текст, но и насколько удобно с ней работать. Если сайт загружается медленно, плохо адаптирован под мобильные устройства или усложняет навигацию, такой источник проигрывает конкуренцию.
ИИ стремится опираться на страницы, которые быстро открываются, корректно отображаются на смартфонах и позволяют без усилий извлечь нужную информацию. Тяжелые страницы с перегруженным дизайном, сложной структурой или техническими ошибками воспринимаются как менее надежные и реже используются при формировании ответа.
Это особенно ощущается в сценариях, где нейросеть предполагает дальнейшее взаимодействие пользователя с сайтом. Если вероятность негативного опыта высока, источник теряет приоритет — даже при сильном контенте.
Что стоит проверить:
- скорость загрузки страниц и работу сайта на слабых соединениях;
- корректную адаптацию под мобильные устройства;
- понятную навигацию и чистоту интерфейса без лишних визуальных элементов.
Техническое состояние сайта становится частью сигнала доверия для ИИ.
Ошибка №7. Нейросети не понимают, почему именно этот бренд стоит упоминать
Даже при сильном контенте бренд может оставаться «невидимым» для нейросетей, если из материалов неясно, какую роль он играет и почему его стоит выделить среди других источников. В таких случаях контент воспринимается как обезличенный справочный массив, а не как позиция конкретного бренда.
Часто проблема не в отсутствии информации, а в отсутствии идентификации. Бренд либо упоминается вскользь, либо растворяется в тексте без четкой связки с темой. Нейросеть видит полезный материал, но не фиксирует, кто именно является его источником и чем он отличается от других.
Дополнительный риск создает несогласованность формулировок. Если в разных материалах бренд описывается по-разному — меняются роли, акценты и позиционирование, — нейросети сложнее выстроить устойчивое представление. В результате бренд не формируется как надежная точка отсчета и реже попадает в ответы.
Что стоит проверить:
- понятно ли из контента, в каком качестве бренд выступает: эксперт, производитель, подрядчик, платформа;
- связаны ли ключевые темы напрямую с брендом, а не существуют сами по себе;
- используются ли устойчивые и согласованные формулировки при описании компании и ее экспертизы.
Если бренд не считывается как самостоятельная и понятная сущность, даже сильный контент не становится основанием для упоминания в ответах.
Ошибка №8. Контент не отвечает на вопросы, с которыми пользователи приходят к нейросетям
Многие материалы выглядят экспертно и глубоко, но построены как статьи или рассуждения, а не как ответы. При этом пользователи все чаще формулируют запросы к нейросетям в виде прямых вопросов: как выбрать, чем отличается, что лучше в конкретной ситуации, на что обратить внимание.
Если в контенте нет явных ответов на такие вопросы, нейросети сложнее использовать его при формировании ответа. Даже сильный текст, насыщенный деталями и аналитикой, может быть проигнорирован, потому что в нем отсутствуют четкие опорные точки, которые можно извлечь и вставить в рекомендацию.
Проблема усиливается, когда ключевые выводы растворены в тексте: спрятаны в середине абзацев, выражены через сложные конструкции или не сформулированы напрямую. Для нейросетей такой контент выглядит как фон, а не как источник готового знания.
Что стоит проверить:
- есть ли в материалах прямые ответы на типовые вопросы пользователей;
- сформулированы ли выводы явно, а не через намеки и рассуждения;
- можно ли извлечь из текста отдельные фрагменты без потери смысла.
Контент, ориентированный на нейросети, не обязан быть упрощенным. Но он должен быть устроен так, чтобы на его основе можно было быстро и точно ответить на вопрос пользователя.
Ошибка №9. Бренд не проверяет, как он выглядит в ответах нейросетей
Контент публикуется, обновляется, масштабируется, но при этом никто не проверяет, упоминается ли бренд в ответах нейросетей и в каком контексте он там появляется.
Нейросети могут:
- не упоминать бренд вовсе;
- упоминать его эпизодически;
- использовать устаревшие или искаженные формулировки;
- отдавать приоритет конкурентам с менее сильным, но лучше структурированным контентом.
Без регулярной проверки эти сигналы остаются незаметными. Команда может считать, что «все сделано правильно», пока нейросети формируют ответы, опираясь на другие источники.
Отдельная проблема — отсутствие сравнения. Без понимания того, кто именно появляется в ответах нейросетей по ключевым сценариям, невозможно оценить реальную конкурентную ситуацию. В таких условиях корректировки контента становятся случайными и не дают устойчивого эффекта.
Что стоит учитывать:
- появляется ли бренд в ответах нейросетей по профильным запросам;
- в каком контексте он упоминается и рядом с какими компаниями;
- какие формулировки используются и совпадают ли они с текущим позиционированием.
Для этого подходит модуль анализа видимости бренда и сайта в ответах нейросетей — инструмент Пиксель Тулс позволяет увидеть фактическое присутствие бренда в нейроответах и зафиксировать точки, где контент теряется или искажается.
Ошибка №10. Контент существует вне единого смыслового контура
Даже сильные материалы могут работать разрозненно. Статьи, кейсы, страницы услуг, публикации на внешних площадках написаны качественно, но не складываются в единую картину. Для нейросетей это выглядит как набор отдельных фрагментов без четкой связи между ними.
Они формируют ответы, опираясь на согласованность сигналов. Если в одном материале бренд выступает как эксперт, в другом — как подрядчик, а в третьем — как абстрактная компания «на рынке», модель не может зафиксировать устойчивую роль. В таких условиях приоритет получают источники с более цельным и повторяемым представлением.
Что стоит проверить:
- согласованы ли формулировки и роли бренда в разных материалах;
- повторяются ли ключевые смыслы и понятия в разных точках входа;
- можно ли проследить логическую связь между контентом на сайте и внешних площадках.
Для нейросетей важна не только сила отдельных материалов, но и их согласованность. Цельный смысловой контур повышает шанс того, что бренд будет восприниматься как устойчивый и надежный источник.
Как работает модуль анализа видимости бренда от Пиксель Тулс
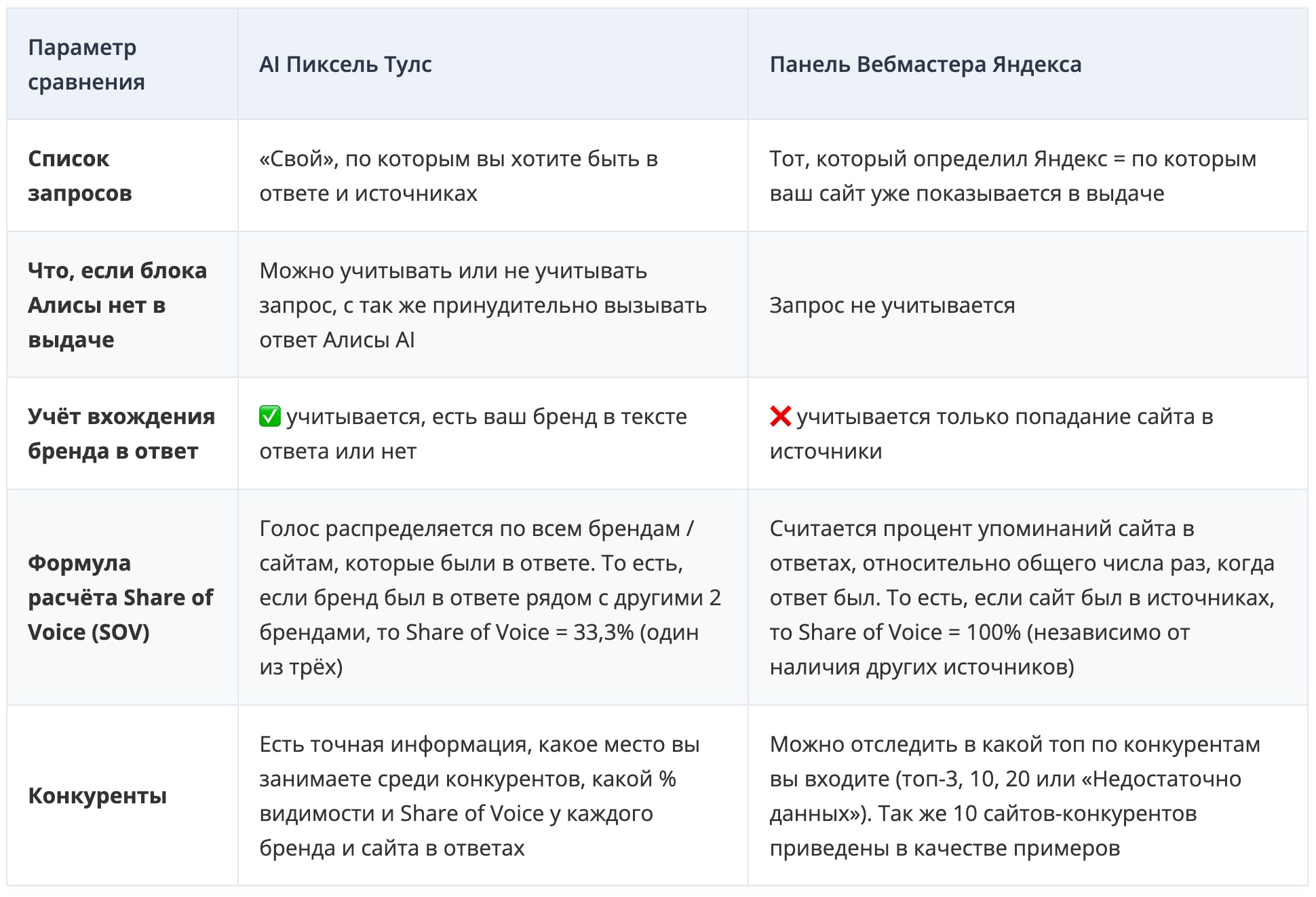
Инструмент выполняет глубокую проверку и дает анализ об упоминании вашего бренда в ответах нейросетей: сколько упоминается, где, в каком контексте, по каким запросам.
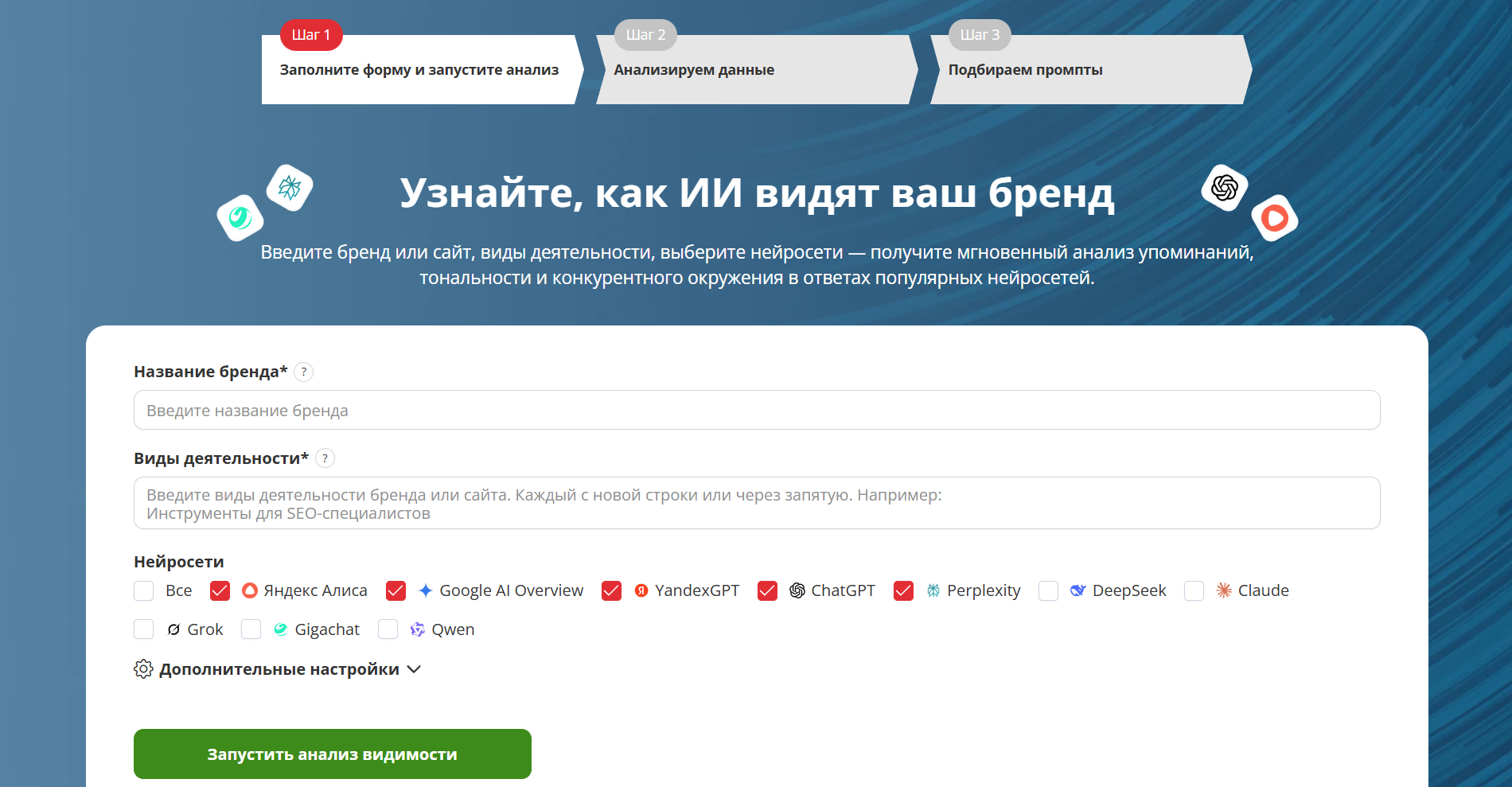
Что нужно сделать для запуска:
- Введите свой бренд или сайт, перечислите виды деятельности
Укажите название и через запятую вкратце опишите, чем занимается компания.
- Анализ данных
Инструмент соберет запросы, по которым вы вероятнее всего можете упоминаться в ответах ИИ. При желании запросы можно дополнить/скорректировать.
- Анализ ответов нейросетей
Инструмент проверяет, как нейросети отвечают на выбранные запросы, и показывает:
- упоминается ли бренд;
- в каком контексте он появляется;
- по каким запросам ваш бренд упоминается в ответах;
- Доступ к результатам в одном интерфейсе
Все данные по видимости, контексту упоминаний и конкурентному окружению собраны в одном месте.
- Настройка регулярных проверок и рекомендаций
Можно сразу задать периодичность анализа и рекомендаций на основе анализа — например, раз в неделю или месяц — и отслеживать, как меняется присутствие бренда в ответах нейросетей после правок контента.
Что дальше?
Нейровыдача пока не работает как рекламный канал. Здесь нет аукционов, ставок и оплаты за клики. Попадание в рекомендации нейросетей зависит от структуры, понятности и полезности контента — без прямых вложений в продвижение.
При этом нейросети уже становятся стабильной точкой входа. Все больше пользователей приходят на сайты не из классической поисковой выдачи, а по рекомендациям ChatGPT, Perplexity, DeepSeek, «Алисы» и других ИИ-ассистентов. Для брендов это означает новый источник трафика и новую среду конкуренции, где решает качество и согласованность сигналов.
Попробуйте мощный инструмент Пиксель Тулс — Модуль анализа видимости бренда и сайта в ответах нейросетей, чтобы оценить фактическое присутствие бренда в нейроответах.
Нейросети уже формируют новый слой поиска. Чем раньше компании начали работать с ним, тем выше шанс быть не просто найденными, а рекомендованными.