AI модель
AI модель — это математический алгоритм, обученный на данных для решения интеллектуальных задач. Она представляет собой цифровой слепок логических связей, извлеченных из примеров. Модель может распознавать образы, прогнозировать события или генерировать тексты. Это «мозг» системы, определяющий ее возможности. В отличие от кода, она не пишется вручную, а формируется в процессе обучения.
Термин «AI-модель» сегодня используют для всего подряд — от чат-бота до рекомендательной ленты в соцсети. Из-за этого он превратился в размытый ярлык, за которым теряется суть. В этой статье разберем, что такое AI-модель на самом деле, чем она отличается от алгоритма и кода, как ее выбрать под конкретную бизнес-задачу и каких ошибок стоит избегать при внедрении.

Что такое AI-модель: точное определение
AI-модель — не программа и не алгоритм в привычном смысле. Это зафиксированный результат обучения: логических связей, которые система получила, обработав большой объем данных. По этим параметрам модель генерирует новые данные, когда к ней поступает запрос.
Когда модель получает запрос, она использует эти параметры для расчета наиболее вероятного результата: текста, изображения, классификации, прогноза или другого ответа.
Важно различать модель, алгоритм и код:
- Алгоритм — это метод обучения системы, по которому она извлекает закономерности.
- AI-модель — уже обученная система, получившая конкретные параметры после работы с данными.
- Код — программная реализация, которая связывает модель с интерфейсами, API, базами данных и бизнес-логикой.
Один и тот же алгоритм может давать совершенно разные результаты в зависимости от данных, на которых обучалась модель. Поэтому в прикладных AI-системах качество данных и процесс обучения обычно важнее выбора самого алгоритма.
На практике качество модели зависит не только от обучения, но и от подготовки данных, настройки параметров, особенностей среды использования и критериев оценки результата.
Из чего состоит AI-модель на практике
Внутри проекта модель включает несколько уровней:
- Первый — параметры. Это числовые значения, веса, коэффициенты или структуры, которые появились в ходе обучения. Именно они позволяют модели «узнавать» похожие ситуации в новых данных.
- Второй — подготовка данных. Перед попаданием в модель данные очищаются, нормализуются, кодируются, агрегируются. Если на этом этапе допущена ошибка, даже сильная модель начнет давать слабый результат.
- Третий — контекст применения. Модель обучалась на определенных данных и ожидает похожую структуру входной информации. Если данные меняются, качество может падать.
- Четвертый — метрики и пороги. Для одной задачи важнее точность, для другой — полнота, для третьей — скорость ответа. Например, в антифроде лучше лишний раз проверить подозрительную операцию, чем пропустить мошенничество. В маркетинговой рекомендации, наоборот, критичнее не раздражать пользователя нерелевантными предложениями.
Основные типы AI-моделей
Классифицировать AI-модели можно по нескольким признакам: по типу задачи, по типу данных на входе, по способу генерации результата. Для практического выбора удобнее всего ориентироваться на задачу.
-
NLP-модели
Понимают и генерируют текст. Включают LLM, модели перевода, классификации тональности, суммаризации.
-
Компьютерное зрение
Распознают объекты, лица, аномалии на фото и видео. Применяются в медицинской диагностике и контроле качества.
-
Прогностические модели
Предсказывают тренды, спрос, цены. Работают с временными рядами и историческими данными.
-
Рекомендательные системы
Анализируют поведение пользователей и предлагают персонализированный контент, товары, сервисы.
-
Обнаружение аномалий
Выявляют отклонения от нормы: мошеннические транзакции, сбои оборудования, нетипичное поведение.
-
Генеративные модели
Создают новый контент: тексты, изображения, видео, код. Работают с одним или несколькими типами данных.
Отдельно стоит выделить одномодальные и мультимодальные модели. Одномодальные принимают только один тип данных — например, текст или аудио. Мультимодальные способны одновременно обрабатывать текст, изображение и звук, что открывает новые возможности для сложных задач: анализ документов с диаграммами, голосовые интерфейсы с визуальным контекстом, автоматическая обработка видеозаписей встреч.
Как обучают AI-модели
Способ обучения определяет, какие задачи сможет решать модель, и насколько устойчиво она будет работать на практике. Существует несколько основных подходов, каждый из которых применяется для разных типов задач и данных.
Обучение с учителем
Модель обучается на размеченных данных, где для каждого примера заранее известен правильный ответ. В процессе обучения система сравнивает свой результат с эталоном и постепенно снижает количество ошибок. Такой подход используется в задачах классификации, машинного перевода, распознавания документов, анализа обращений клиентов и прогнозирования.
Обучение без учителя
В этом случае модель работает с неразмеченными данными и самостоятельно ищет закономерности, сходства и скрытые структуры. Метод применяется для сегментации аудитории, поиска аномалий, анализа поведения пользователей и выявления скрытых зависимостей в больших массивах данных.
Обучение с подкреплением
Модель обучается через систему поощрений и штрафов. За успешные действия она получает положительную оценку, за ошибки — отрицательную. Постепенно система начинает выбирать наиболее эффективные стратегии поведения.
Один из распространенных вариантов — RLHF (Reinforcement Learning from Human Feedback), где качество ответов дополнительно оценивают люди. Этот подход используется при настройке современных языковых моделей.
Transfer Learning и Fine-Tuning
Во многих случаях модель не обучают с нуля. Вместо этого берут уже существующую базовую модель и адаптируют ее под конкретную задачу или отрасль. Такой подход позволяет существенно сократить объем данных, время разработки и вычислительные ресурсы.
Глубокое обучение
Основано на многослойных нейронных сетях, способных самостоятельно выявлять сложные зависимости в данных. Именно этот подход лежит в основе большинства современных генеративных систем: языковых моделей, систем компьютерного зрения, голосовых ассистентов и мультимодальных AI-платформ.
Важно! Высокая точность на тестовых данных еще не гарантирует стабильную работу модели в реальной среде. На практике данные часто отличаются от обучающей выборки: меняются форматы, появляются шумы, редкие сценарии и новые типы запросов. Поэтому перед внедрением AI-системы обязательно проверяют на реальных данных и рабочих сценариях.
Где и как применяются в бизнесе
AI-модели давно вышли за пределы технологических компаний. Сегодня их внедряют в ритейле, промышленности, финансах, медицине, логистике — везде, где есть данные и повторяющиеся решения.
|
Отрасль |
Задача |
Тип модели |
Измеримый результат |
|---|---|---|---|
|
Ритейл |
Прогнозирование спроса |
Прогностическая модель |
Снижение избытка и дефицита товаров, оптимизация закупок |
|
Финансы |
Обнаружение мошенничества |
Модель обнаружения аномалий |
Сокращение потерь от fraud в реальном времени |
|
Медицина |
Диагностика по снимкам |
Модель компьютерного зрения |
Ускорение и повышение точности диагностики |
|
E-commerce |
Персональные рекомендации |
Рекомендательная система |
Рост среднего чека и конверсии |
|
Телеком / поддержка |
Чат-бот первой линии |
Языковая модель (LLM) |
Снижение нагрузки на операторов, рост удовлетворенности |
|
Производство |
Контроль качества продукции |
Модель компьютерного зрения |
Снижение брака, сокращение ручных проверок |
|
HR и рекрутинг |
Скрининг резюме и ранжирование кандидатов |
NLP-модель |
Ускорение найма, снижение субъективности |
|
Маркетинг |
Генерация контента и A/B-гипотез |
Генеративная языковая модель |
Сокращение времени на создание материалов |
Важно понимать, что AI-модель не всегда является центральным элементом системы. В задачах компьютерного зрения, NLP или прогнозирования она действительно стоит в ядре. Но во многих других случаях ключевой вклад вносят правильная постановка задачи, качество данных и интеграция в существующие процессы. Модель — лишь один из компонентов, а не волшебная кнопка.
Чек-лист выбора AI-модели
- Задача четко сформулирована: что именно модель должна предсказывать или генерировать?
- Определен тип данных: текст, изображения, таблицы, временные ряды — или их комбинация?
- Оценено требование к скорости ответа: реальное время (чат, антифрод) или офлайн-обработка (аналитика)?
- Проверены требования к конфиденциальности: можно ли отправлять данные во внешнее API или нужен on-premise?
- Просчитан бюджет: стоимость вычислений, разметки данных, поддержки модели и команды.
- Оценена масштабируемость: как модель поведет себя при росте нагрузки в 10 раз?
- Определены метрики успеха: точность, задержка, процент правильных ответов — что важнее в вашей задаче?
- Проверена совместимость с IT-инфраструктурой: API, базы данных, бэкенд, системы безопасности.
Типичные ошибки при внедрении AI-моделей
Большинство неудачных AI-проектов провалились не из-за плохого алгоритма, а из-за системных ошибок в подходе. Вот самые распространенные из них.
-
Ошибка 1 — Начать с технологии, а не с задачи
«Хотим внедрить GPT» — неправильная постановка. Правильная: «хотим сократить время обработки обращений на 40%». Технология выбирается под задачу, а не наоборот.
-
Ошибка 2 — Недооценить качество данных
В реальных проектах подготовка данных занимает 60-80% всего времени. Плохие данные дадут плохую модель, сколько бы ресурсов ни вложили в обучение.
-
Ошибка 3 — Игнорировать дрифт после запуска
Модель, точная в день внедрения, может заметно деградировать через 3-6 месяцев из-за изменений в данных и поведении пользователей. Без мониторинга это остается незамеченным.
-
Ошибка 4 — Путать точность на тесте с готовностью к продакшену
Модель, показавшая 95% точности на тестовой выборке, может вести себя хуже на реальных данных из-за распределений, не представленных в обучающем наборе.
-
Ошибка 5 — Ждать универсального решения
Готовые «коробочные» модели редко дают ожидаемый результат без адаптации. Даже незначительные отличия в данных по формату или шуму ведут к снижению качества. Fine-tuning или кастомное обучение — почти всегда необходимость, а не опция.
-
Ошибка 6 — Не учитывать конфиденциальность данных при обучении
Передача чувствительных клиентских данных во внешние API без анонимности или шифрования — распространенная ошибка, которая несет юридические и репутационные риски.

AI-модели и продвижение бренда в нейросетях
В 2026 году все больше пользователей идут за ответами в ChatGPT, Claude, Gemini, Perplexity — вместо того чтобы переходить на сайты из поисковой выдачи. Это создает новую задачу для бизнеса: попасть в ответы, которые генерируют нейросети.
AI-модели, которая лежат в основе этих систем, обучаются на текстах из открытого доступа и формируют ответы на основе паттернов, извлеченных из миллиардов документов. Это означает, что компании, которые создают авторитетный, структурированный и цитируемый контент по своей теме, имеют больше шансов быть упомянутыми в AI-ответах.
Практические рекомендации для попадания в AI-ответы:
- Создавайте экспертные материалы, которые полно отвечают на ключевые вопросы отрасли — именно такие тексты модели склонны воспроизводить.
- Используйте структурированные данные и четкую семантическую разметку — LLM лучше извлекают факты из хорошо структурированного контента.
- Формируйте цитируемость: пресс-релизы, исследования, данные с указанием источника повышают вероятность упоминания бренда в сгенерированных ответах.
- Используйте AI-инструменты для мониторинга упоминаний бренда в ответах нейросетей.
- Обеспечивайте актуальность контента: модели с интернет-доступом (поисковые агенты) отдают предпочтение свежим и регулярно обновляемым материалам.
Каким должен быть подход к AI-моделям
Работа с AI-моделями не заканчивается после обучения и запуска. Чтобы модель действительно приносила пользу бизнесу, нужен понятный и управляемый процесс.
На практике это означает, что компания заранее определяет:
- кто отвечает за работу модели;
- какие данные можно использовать для обучения;
- по каким метрикам оценивается качество;
- как проверяются ошибки и спорные результаты;
- как часто модель нужно обновлять;
- что делать, если качество начинает снижаться.
Без такой системы AI-проект часто остается экспериментом: модель может хорошо работать в тестовой среде, но начать ошибаться при реальной нагрузке, изменении данных или новых сценариях использования.
Обычно работа с AI-моделью строится по циклу:
Данные → обучение → проверка → внедрение → мониторинг → переобучение → улучшение процесса.
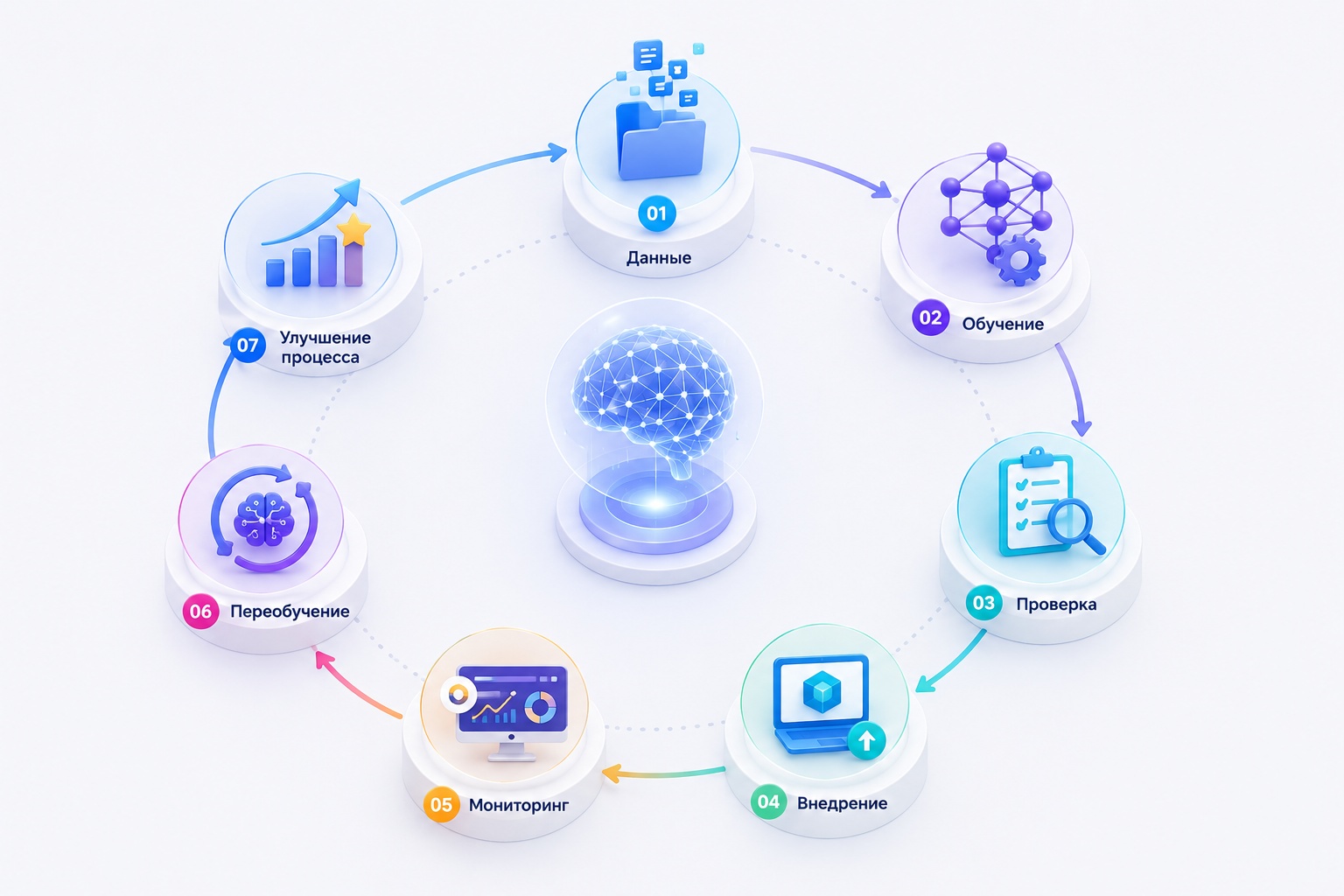
Сначала компания собирает данные. Затем модель обучают и проверяют на тестовых примерах. После этого ее внедряют в продукт, сервис или внутренний процесс. Но на этом работа не заканчивается: модель продолжают контролировать уже в реальной эксплуатации.
Например, анализируют:
- насколько точными остаются ответы;
- увеличилось ли количество ошибок;
- изменилось ли поведение пользователей;
- появились ли новые типы запросов или данных.
Если качество начинает снижаться, модель переобучают или адаптируют под новые условия.
Также важно фиксировать основную информацию о модели: на каких данных она обучалась, какая версия используется, какие метрики были при запуске, какие ограничения есть у системы и кто отвечает за ее поддержку.
Такой подход помогает использовать AI-модель как полноценный рабочий инструмент, а не как «черный ящик», поведение которого невозможно контролировать или объяснить.