LLM (Large Language Model): что это такое и как работает
LLM (Large Language Model) — это тип нейросети для обработки естественного языка. Она обучается на гигантских объемах текстовых данных. Модель умеет понимать, генерировать и переводить тексты. Она предсказывает следующее слово в предложении. Это делает ее похожей на человека. Сегодня это фундамент для всех нейросетей.
Большая языковая модель — технология, которая за несколько лет превратилась из разработки для исследовательских лабораторий в один из главных инструментов цифровой экономики. Она лежит в основе чат-ботов, ИИ-поиска, генераторов текстов, корпоративных ассистентов и сервисов автоматизации. Разбираем, что такое LLM, как она устроена внутри, где реально применяется в бизнесе, какие ошибки допускают при внедрении и как использовать ее для продвижения бренда в нейросетевых ответах.

Что такое LLM
LLM (Large Language Model, большая языковая модель) — это класс систем искусственного интеллекта, предназначенных для работы с естественным языком. Такие модели обучаются на огромных массивах текстов, чтобы распознавать закономерности в языке, понимать контекст и формировать ответы, близкие по структуре к человеческой речи.
В основе работы LLM лежит обучение на текстовых данных. Модель анализирует последовательности слов и постепенно учится прогнозировать, какое слово или фраза с наибольшей вероятностью должны следовать дальше. По мере увеличения объема данных и числа параметров точность таких прогнозов растет, благодаря чему ответы становятся более связными и логичными.
Благодаря таким способностям языка LLM используются в чат-ботах, системах автоматического перевода, генераторах текстов, поисковых сервисах, виртуальных ассистентах и инструментах для обработки документов. Интерес бизнеса к этой технологии продолжает расти: аналитики прогнозируют дальнейшее расширение мирового рынка LLM и увеличение числа корпоративных решений, основанных на больших языковых моделях.
Ключевое отличие от классических алгоритмов
LLM не следует набору прописанных правил — она обнаруживает статистические закономерности в языке самостоятельно. Именно поэтому одна и та же модель справляется и с юридическим аудитом, и с написанием стихов, и с отладкой кода.
Рынок LLM: цифры и тренды

По прогнозам аналитиков Straits Research, к 2033 году мировой рынок превысит $84 млрд. На уровне продуктов к началу 2026 года уже появилось около 750 млн приложений с интеграцией LLM — фактически каждое четвертое мобильное или веб-приложение будет «разговаривать» с пользователем на человеческом языке. Российский сегмент отстает от мирового темпа (25% против 30-35% в год) из-за санкционных ограничений на GPU и дефицита специалистов, однако сохраняет устойчивый рост.
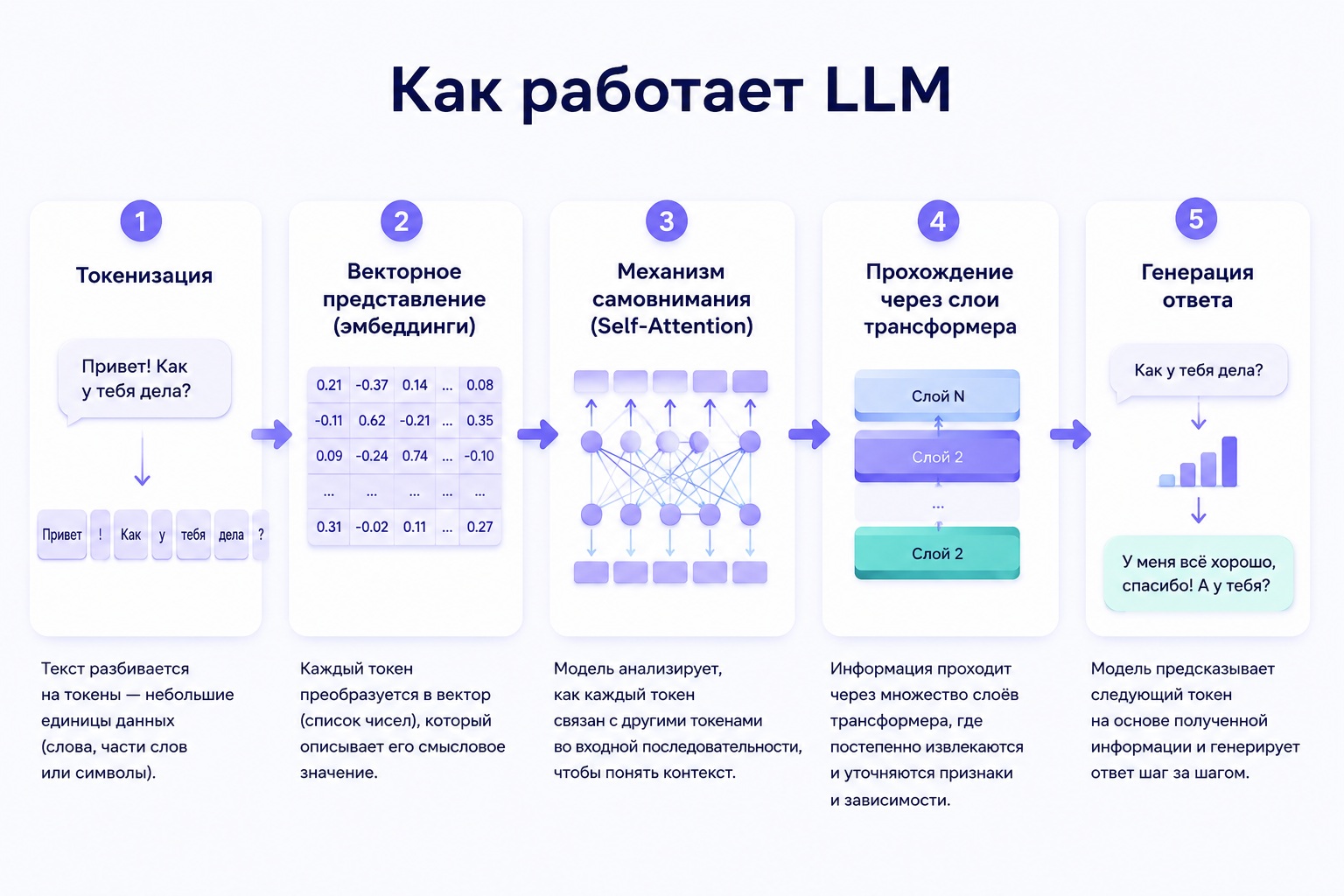
Как LLM работает внутри: механизм за 5 шагов
1. Токенизация
Входной текст разбивается на токены — минимальные единицы обработки. Токеном может быть слово, часть слова, символ или пробел. Фраза «большая языковая модель» превращается в числовую последовательность, понятную нейросети.
2. Векторное представление (эмбеддинги)
Каждый токен преобразуется в вектор — точку в пространстве с сотнями измерений. Слова со схожим смыслом оказываются рядом. На этом этапе модель «понимает», что «врач» и «доктор» — почти одно и то же.
3. Механизм самовнимания (Self-Attention)
Ключевое изобретение архитектуры Transformer. Модель вычисляет, насколько каждый токен «важен» для понимания каждого другого. Это позволяет улавливать связь между словами, даже если они стоят далеко друг от друга в тексте.
4. Прохождение через слои трансформера
Информация проходит через десятки (иногда сотни) слоев нейросети. На каждом слое модель уточняет свое «понимание» текста — от синтаксиса к семантике, от фактов к логике.
5. Генерация ответа
На выходе модель предсказывает следующий токен с определенной вероятностью. Процесс повторяется токен за токеном до завершения ответа. Параметр «температура» управляет случайностью: низкая = точнее и предсказуемее, высокая = креативнее.
Современные LLM проходят дополнительный этап — Reinforcement Learning from Human Feedback. Реальные люди оценивают ответы модели, и нейросеть обучается генерировать более полезные, безопасные и точные тексты. Именно RLHF превращает «сырую» модель в удобного ассистента.
Виды LLM и ключевые архитектуры
Типы по доступности
- Закрытые (Proprietary) — ChatGPT, Claude, Gemini. Доступны через API, исходный код закрыт. Как правило, такие модели отличаются более высокой стабильностью и производительностью, но не позволяют развернуть систему локально или полноценно доработать ее под собственную инфраструктуру. Чаще используются для корпоративных ассистентов, продуктовых интеграций и облачных сервисов.
- Открытые (Open Source) — Llama, Mistral, GigaChat. Модели доступны для локального развертывания и адаптации под внутренние задачи компании. Подходят для работы с конфиденциальными данными, кастомизации и интеграции в собственную инфраструктуру без передачи информации сторонним сервисам.
- Специализированные — Med-PaLM, Codex, LexGPT. Это модели, дополнительно обученные на данных конкретной отрасли: медицины, права, программирования и других профессиональных сфер. Благодаря узкой специализации они показывают более высокую точность в профильных задачах и применяются в отраслевых решениях с повышенными требованиями к качеству ответов.
- Мультимодальные — GPT-5.4, Gemini 3.1, Claude 4.6. Работают не только с текстом, но и с изображениями, аудио и видео. Такие модели используются для анализа документов, обработки медиаконтента и сложных сценариев, где необходимо одновременно учитывать несколько типов данных.
Основные архитектурные семейства
- Transformer. Архитектура, предложенная в работе Attention Is All You Need (Vaswani et al., 2017), стала основой большинства современных LLM. Главная особенность Transformer — механизм самовнимания (Self-Attention), который позволяет модели анализировать весь контекст текста одновременно, а не последовательно. Благодаря этому нейросеть лучше улавливает связи между словами и понимает длинные последовательности текста.
- GPT (Decoder-only). GPT расшифровывается как Generative Pre-trained Transformer. Такие модели используют декодер трансформера и ориентированы прежде всего на генерацию текста. GPT предсказывает следующий токен на основе предыдущего контекста, благодаря чему может поддерживать диалог, писать статьи, генерировать код и отвечать на вопросы. На этой архитектуре построены ChatGPT и многие современные чат-боты.
- BERT (Encoder-only). BERT (Bidirectional Encoder Representations from Transformers) разработан для глубокого понимания текста и анализа контекста сразу в обоих направлениях. Такие модели хорошо подходят для поиска информации, классификации текстов, анализа тональности и извлечения данных, однако используются для генерации текста значительно реже.
- T5 / Encoder-Decoder. T5 (Text-to-Text Transfer Transformer) рассматривает любую задачу обработки языка как преобразование одного текста в другой. Архитектура сочетает кодировщик и декодер, поэтому подходит для перевода, ответов на вопросы и создания нового контента.
LLM и смежные понятия: в чем разница
| Понятие | Что делает | Ключевое отличие от LLM |
|---|---|---|
| Поисковый алгоритм | Ищет и ранжирует готовые страницы по запросу |
Не генерирует текст — только находит существующий. Навигатор по чужим мыслям. |
| База данных | Хранит и возвращает точные структурированные данные |
Не интерпретирует и не строит связи.Отвечает только на то, что было явно записано. |
| Традиционный ML | Классифицирует или предсказывает по обучающим примерам |
Узкоспециализирован: одна задача — одна модель.Плохо переключается между контекстами. |
| PRA (роботизация) | Автоматизирует повторяемые действия в интерфейсах |
Следует жестким правилам.Ломается при малейшем изменении формы или процесса. |
| RAG-система | LLM + поиск по корпоративной базе знаний в режиме реального времени |
Не самостоятельная технология, а паттерн использования LLM.Снижает галлюцинации. |
| LLM-агент | LLM, которой дан доступ к инструментам: браузеру, API, файлам |
Расширение LLM, а не замена.Позволяет выполнять многошаговые автономные задачи. |
Применение LLM в бизнесе
Практическая ценность LLM — в способности работать с неструктурированными текстовыми данными в любом масштабе. Именно это делает технологию применимой почти в любой сфере.
1. Чат-боты и клиентская поддержка
Большие языковые модели позволяют создавать чат-ботов, которые понимают запросы в свободной форме и поддерживают диалог без жестких сценариев и кнопочных меню. Пользователь может сформулировать вопрос своими словами, а модель анализирует контекст и подбирает подходящий ответ.
Такие системы используют для обработки типовых обращений: проверки статуса заказа, возврата товара, регистрации на рейс, поиска информации о доставке или тарифах. Это снижает нагрузку на операторов и сокращает время ожидания ответа.
Например, авиакомпания Delta использует чат-бот Ask Delta на базе LLM для работы с запросами о рейсах, багаже и регистрации. По данным компании, внедрение такого ассистента помогло сократить нагрузку на колл-центр примерно на 20%.
2. Генерация и адаптация контента
LLM применяются для подготовки текстов, редактирования материалов и адаптации контента под разные форматы и аудитории. Модели могут создавать черновики статей, писать описания товаров, подбирать заголовки, делать краткие выжимки из документов и помогать с локализацией материалов на другие языки.
Такие инструменты полезны в медиа, маркетинге и e-commerce, где требуется быстро обрабатывать большие объемы контента. При этом LLM обычно используются как вспомогательный инструмент: модель ускоряет рутинные задачи, а финальная редактура остается за человеком.
Один из известных примеров — система Heliograf, которую использовала редакция Washington Post. Модель помогала журналистам готовить черновики новостей, подбирать заголовки и суммировать информацию, что ускоряло публикацию материалов и освобождало время для аналитической работы.
3. Анализ тональности и исследование рынка
LLM помогают компаниям анализировать большие массивы пользовательских отзывов, комментариев и сообщений из социальных сетей. Модель определяет эмоциональную окраску текста, выделяет повторяющиеся проблемы и показывает, как аудитория воспринимает бренд, продукт или рекламную кампанию.
Такой анализ используют для мониторинга репутации, оценки реакции на запуск новых продуктов и выявления негативных тенденций на раннем этапе. Вместо ручной обработки тысяч сообщений компания может получить структурированную картину за несколько минут.
Например, модели могут анализировать отзывы в интернет-магазинах, комментарии в Telegram или обсуждения в соцсетях и показывать, какие темы вызывают недовольство пользователей чаще всего: доставка, качество сервиса, цена или работа поддержки.
Функциональная ценность для бизнеса
| Задача | Было (без LLM) | Стало (с LLM) | Эффект |
|---|---|---|---|
| Резюме длинного документа | 1-3 часа для сотрудника | 30 секунд | ×360 быстрее |
| Первичный разбор входящих заявок | Оператор-человек | Автоматически 24/7 | −60-80% затрат |
| Создание черновиков контента | Копирайтер 4-8 ч | LLM 5 мин + правка | ×5-10 производительность |
| Анализ тональности 10 000 отзывов | Недели ручной разметки | До 5 минут | Новые инсайты в реальном времени |
| Перевод на 50 языков | Команда переводчиков | Один API-вызов | −90% затрат на локализацию |
Частые ошибки при внедрении LLM
По данным исследования Shao et al. около 77% коммерческих LLM-приложений содержат серьезные ошибки — от некорректных API-интеграций до архитектурных уязвимостей. Большинство из них типичны и предсказуемы.
- Использовать ответы модели без дополнительной проверки. LLM может формировать убедительные, но неточные ответы, особенно в темах, где важна фактическая точность: медицине, финансах, праве или технической документации. → Для критически важных задач обычно используют проверку ответов человеком, а также подключение модели к верифицированным источникам данных через RAG.
- Запускать модель без инструкций и контекста. Без ограничений и системных настроек модель может отвечать в неподходящем стиле, уходить от темы или давать нестабильные результаты. → Перед внедрением важно задать системный промпт: роль модели, формат ответа, ограничения и правила работы с запросами.
- Передавать конфиденциальные данные в публичные сервисы. В открытые API не рекомендуется отправлять персональные данные клиентов, внутренние документы или коммерчески чувствительную информацию без отдельной политики безопасности и соглашений с провайдером. → Для работы с такими данными компании чаще используют локальные модели или корпоративные версии сервисов с отдельными условиями хранения и обработки информации.
- Ожидать высокой точности без настройки модели. Базовая LLM не знает внутренние процессы компании, отраслевую терминологию и особенности конкретного бизнеса. Без дополнительного контекста качество ответов может быть нестабильным. → Обычно для повышения точности используют дообучение, RAG-системы и наборы внутренних данных.
- Не учитывать ограниченность обучающих данных. Модель обучается на информации, доступной на определенный момент времени, поэтому может не знать о новых событиях, изменениях законодательства или актуальных ценах. → Для работы с постоянно обновляемой информацией модели подключают к внешнему поиску, API или корпоративным базам знаний.
LLM и продвижение бренда в нейросетевых ответах
Если раньше пользователи искали ответы на интересующие вопросы в Google или Яндекс, то сейчас они сразу идут в ChatGPT, Claude, Perplexity или другие нейросети. LLM при генерации ответа «выбирает» компании и бренды, которые присутствуют в обучающих данных и индексируемом контенте. Это создает новый канал продвижения — Generative Engine Optimization (GEO).
Как LLM выбирает бренды для упоминания
Модель склонна упоминать компании, которые:
- часто встречались в авторитетных источниках в период обучения (СМИ, отраслевые издания, Википедия);
- имеют четкое семантическое поле — понятно, чем занимаются и в каком сегменте;
- связаны с конкретными кейсами и результатами, описанными в открытых источниках;
- упоминаются в контексте экспертизы: исследования, публикации, комментарии специалистов.
Практический чек-лист: как сделать бренд «видимым» для LLM
- Публикуйте экспертный контент с четкими формулировками того, что вы делаете и для кого. LLM хорошо извлекает структурированные описания продуктов и услуг.
- Добивайтесь упоминаний в авторитетных отраслевых изданиях, рейтингах и исследованиях — именно эти источники попадают в обучающие данные моделей.
- Описывайте реальные кейсы с конкретными цифрами. «Сократили время обработки заявок с 3 дней до 20 минут» лучше запоминается моделью, чем абстрактное «повысили эффективность».
- Структурируйте страницы сайта так, чтобы ответы на ключевые вопросы аудитории были явными и конкретными — LLM извлекает именно такие блоки для RAG-систем с доступом в интернет.
- Создавайте глоссарии, руководства и FAQ по тематике вашего бизнеса. Информационный контент чаще индексируется и попадает в контекст нейросетевых ответов.
Пример применения
Юридическая фирма, которая публично описала кейс автоматизации аудита договоров с конкретными результатами («риски обнаруживаются за 1 минуту вместо 3 дней»), с высокой вероятностью окажется в ответе нейросети на вопрос «какие компании используют LLM в юриспруденции». Абстрактное «мы работаем с ИИ» в ответ не попадет.
Что будет дальше: перспективы LLM

По оценке сооснователя OpenAI Андрея Карпаты, следующие поколения LLM не станут общим ИИ, но продолжат быстро совершенствоваться и захватывать еще больше профессиональных задач.
Итог: LLM в трех тезисах
1. LLM — это технология обработки языка, а не «понимающий» интеллект.
одель анализирует огромные массивы текстов и прогнозирует наиболее вероятное продолжение фразы. За счет этого она может писать связные тексты, отвечать на вопросы, переводить и работать с документами.
2. Главная ценность LLM — работа с большими объемами неструктурированных данных.
Документы, переписка, отзывы, отчеты и базы знаний обрабатываются значительно быстрее, чем при ручной работе, что помогает автоматизировать рутинные задачи и ускорять процессы.
3. Максимальный эффект дает не сама модель, а ее интеграция в бизнес-процессы.
LLM приносит результат, когда используется вместе с внутренними данными, понятными сценариями применения, контролем качества и измеримыми бизнес-метриками.